ElasticSearch DSL 语句
ES 的 Restful 语法
ES 几种常见的请求方式,与我们的传统的 Restful 有区别
# get请求(获取数据)
http://ip:port/index # 查询 es 的 index
http://ip:port/index/type/doc_id # 根据文档 id 查询指定文档的信息
# post请求
http://ip:port/index/type/_search # 查询文档,可以在请求体中添加 json 字符串的内容,代表查询条件
http://ip:port/index/type/doc_id/_update # 修改文档 ,在请求体中指定 json 字符串,代表修改条件
# put请求
http://ip:port/index # 创建索引,请求体中指定索引的信息
http://ip:port/index/type_mappings # 创建索引,然后指定索引存储文档的属性
# delete请求
http://ip:port/index # 删除索引(删库跑路~)
http://ip:port/index/type/doc_id # 删除指定的文档
field 的类型
前面说了 ES 的 field 和数据库的字段类似,所以它也有类型之分
字符串类型
text # 最常用,一般用于全文检索,会给 field 分词
keyword # 不会给 field 进行分词(就是关键字,例如地名,人名,手机号之类的)
数值类型
long
integer
short
byte
double
float
half_float # 精度比 float 小一半,float 是 32 位,这个是 16 位
scaled_float # 根据 long 类型的结果和你指定的 secled 来表达浮点类型:long:123 ,secled:100,结果:1.23
时间类型
date # 可以指定具体的格式 "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
布尔类型
boolean # false true
二进制类型
binary # 基于base64的二进制
范围类型
integer_range # 赋值时,无需指定具体内容,只需存储一个范围即可,指定 gt、lt、gte、lte
double_range
long_range
float_range
data_range
ip_range
经纬度类型
geo_point # 存储经纬度
ip类型
ip # v4 v6都可以
操作索引
创建索引
更详细的创建看下面 “创建索引以及 Type” 那一节
// 1 创建名为 parson 的索引
PUT /parson
{
"settings": {
"number_of_shards": 5, // 默认分片为5
"number_of_replicas": 1 // 默认备份为1
}
}
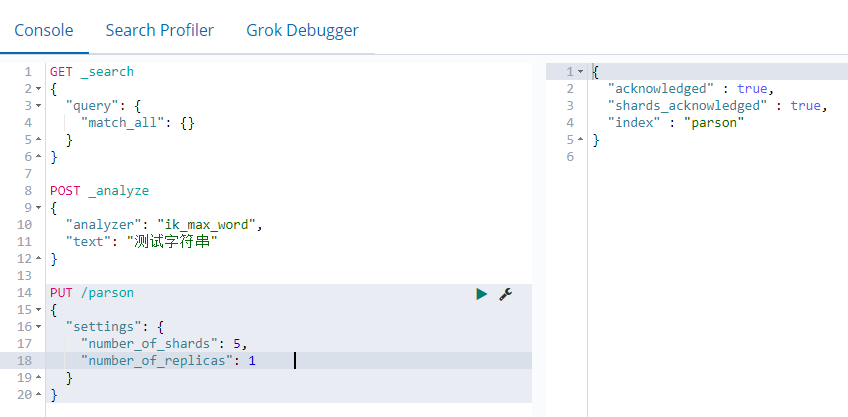
然后可以在 Management 里面找到刚创建的索引
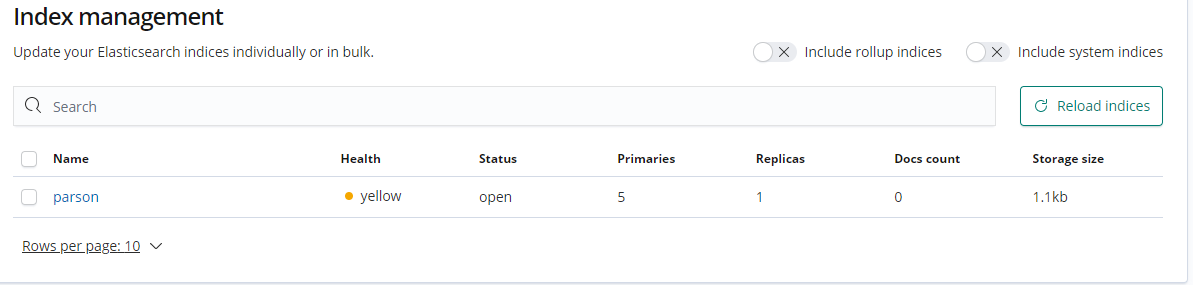
也可以通过 GET 请求来查看索引信息
// 2 查看索引,可以通过图形界面,也可以通过发请求来查看,信息如下:
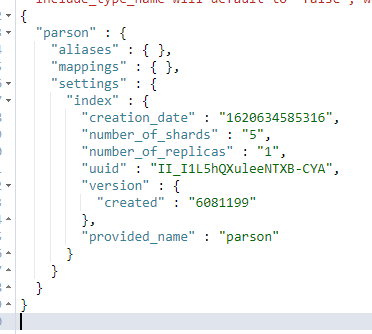
GET /parson
删除索引
两种方法,一种是直接在 Management 里面找到这个索引选中删除,另一种则是使用 DELETE 请求
DELETE /parson
获取所有索引库信息
GET _cat/indices?v
创建索引以及 Type
分片(shard):因为 ES 是个分布式的搜索引擎,所以索引通常都会分解成不同部分,而这些分布在不同节点的数据就是分片。ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配,所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是 20亿。
Integer.MAX_VALUE - 128 = 2,147,483,519
副本(replica):ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy.
PUT /book
{
"settings": {
"number_of_shards": 5, // 分片数(默认 5)
"number_of_replicas": 1 // 备份分片数目(默认 1)
},
"mappings": { // 指定数据结构
"novel":{ // 指定索引 Type 为 novel
"properties":{ // 文档存储的 field
"name":{ // 属性名
"type": "text", // 属性的类型
"analyzer": "ik_max_word", // 使用 ik 分词器
"index": true, // 当前 field 可以作为查询条件
"store": false // 是否需要额外的存储
},
"author":{
"type": "keyword"
},
"count":{ // 价格
"type": "long"
},
"onSale":{ // 图书的上架时间
"type": "date",
// 写入多种格式,每种格式都会依次尝试转换,直到有匹配的为止
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" // 三种格式都可以
},
"descr": { // 说明
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
案例二:这里创建了两个 type:people、transactions
{
"data": {
"mappings": {
"people": {
"properties": {
"name": {
"type": "string",
},
"address": {
"type": "string"
}
}
},
"transactions": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"message": {
"type": "string"
}
}
}
}
}
}
文档的操作
添加文档
文档以 _index、_type、_id,三个内容来确定唯一的一个文档(唯一标识)
自动生成 ID 的方式:
POST /book/novel
{
"name": "三体",
"author": "刘慈欣",
"count": 100000,
"on-sale": "2010-01-01",
"descr": "这是一部硬科幻小说~"
}
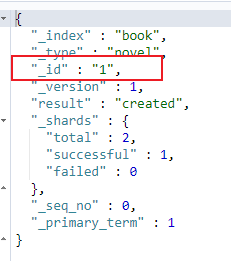
执行后可以发现它自动生成了这个 id

不过这样的 id 不好记(如上图所示的 _id),所以一般都是手动指定
PUT /book/novel/1 // 注意这里是 PUT 后面跟着一个 id
{
"name": "矛盾论",
"author": "毛泽东",
"count": 20000,
"on-sale": "1935-01-01",
"descr": "毛泽东的书~"
}
生成的结果如下:
修改文档
覆盖式修改 PUT 请求
PUT /book/novel/1 // 也就是我们指定id添加的那个,如果重复执行会将老的覆盖
{
"name": "矛盾论",
"author": "毛泽东",
"count": 20000,
"on-sale": "1935-01-01",
"descr": "矛盾是什么等等"
}
doc 修改字段 POST 请求
POST /book/novel/2/_update
{
// 这个 doc 是固定的
"doc": { // 里面指定要修改的键值
"name": "时间移民"
}
}
查看文档
要看到全部数据可以通过 Management 里的
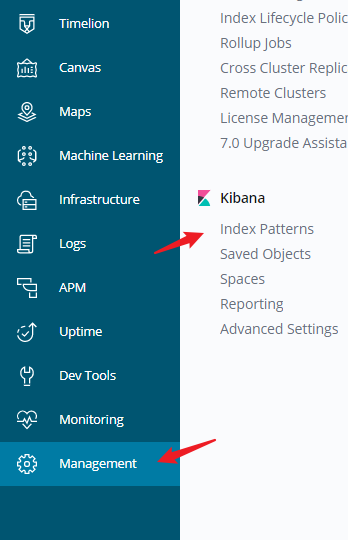
然后一步步的填写
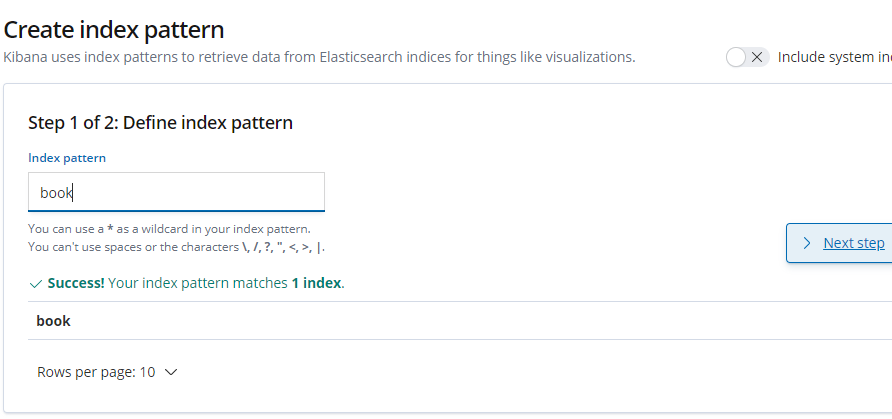
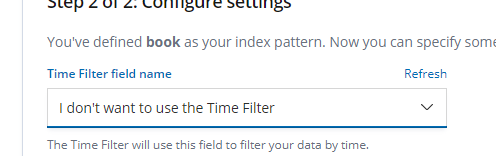
再回到 Discover 就可以看到数据了
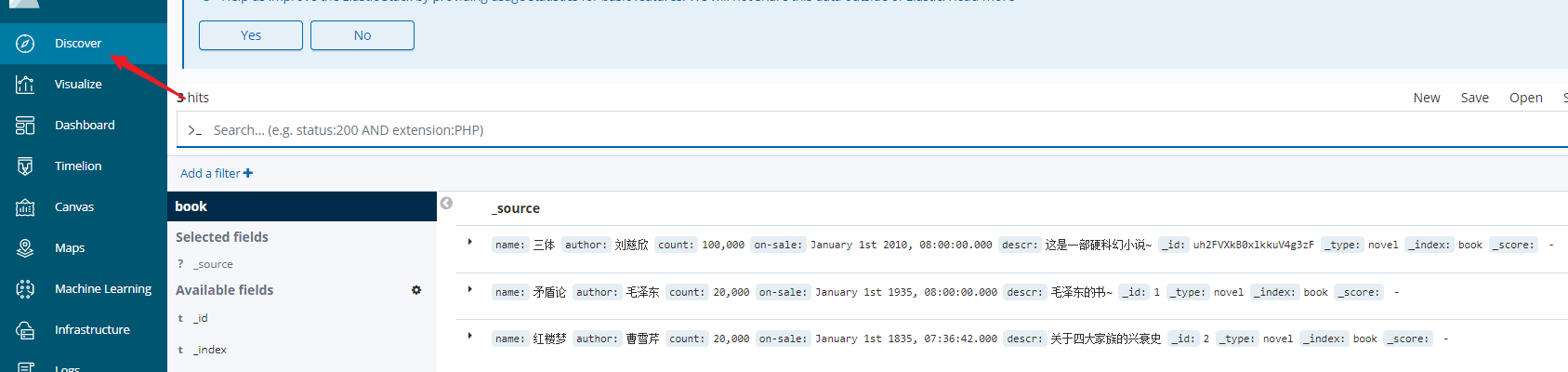
删除文档
DELETE /book/novel/szANLXYBuLPYwN8oa5RL # 根据索引类型id确定到doc然后删除
Sort 排序
// 搜索排序
GET /user/_search
{
"query": {
"match_all": {}
},
"sort": {
"age": {
"order": "desc" # asc升序 desc 降序
}
}
}
分页查询
GET /user/_search
{
"query": {
"match_all": {}
},
"sort": {
"age": {
"order": "desc"
}
},
"from": 0,
"size": 2
}
from 是从 N 的记录开始查询 size 每页显示条数
关键词查询
普通查询 match
# match会对搜索词进行分词,然后对分词后的结果进行搜索
GET _search
{
"query": {
"match": {
字段名: 搜索词
}
}
}
例如
GET /topics/_search
{
"query": {
"match": {
"name": "张三"
}
}
}
我们使用 match 和默认分词器,会把张三进行分词,分成张、三、张三进行检索 会匹配到的结果有
张三
张三丰
张飞
三德子
张二丰
马三丰
多个字段搜索 multi_match
# multi_match 查询允许你做match查询的基础上同时搜索多个字段
GET _search
{
"query": {
"multi_match": {
"query": 搜索词,
"fields": [
字段1,
字段2
……
]
}
}
}
精确查询 term
# term 是精确查询,查询过程中不会对搜索词进行分词,所以搜索词必须是文档分词集合中的一个
GET _search # 查询所有索引中的数据
或者 GET index_name/_search # 查询一个索引下的所有数据
或者 GET index_name/type_name/_search # 查询一个索引下的一个Type下的所有数据
{
"query":{
"term":{
字段名:搜索词
}
}
}
# terms 允许多个Term,也不会分词
{
"query":{
"terms":{
字段名:
[
字段值1,
字段值2
]
}
}
}
前缀匹配查询 prefix
# prefix:前缀匹配,所有以特定搜索词开头的内容
GET _search
{
"query": {
"prefix": {
字段名 : 搜索词
}
}
}
模糊查询 fuzzy
GET /topics/_search
{
"query": {
"fuzzy": {
"title": "weather"
}
}
}
使用 fuzzy 就像百度一样,你输入个 “邓子棋”,也能把 “邓紫棋” 查出来,有一定的纠错能力
加 .keyword 是要匹配完整的词
GET /topics/_search
'{
"query": {
"fuzzy": {
"name.keyword": "张三"
}
}
}
会匹配到的结果有
张三
张三丰
张飞
张二丰
马三丰
通配符查询 wildcard
GET /topics/_search
{
"query": {
"wildcard": {
"name.keyword": "张三*"
}
}
}
使用 wildcard 相当于 SQL 的 like,前后都可以拼接 *,表示匹配 0 到多个任意字符加 .keyword 是要匹配完整的词,会匹配到的结果有
张三
张三丰
过滤查询
多字段查询(组合查询)
这时就应该使用组合查询:bool 查询
must 子句:文档必须匹配 must 查询条件(AND); should 子句:文档应该匹配 should 子句查询的一个或多个(OR); must_not 子句:文档不能匹配该查询条件(NOT); filter 子句:过滤器,文档必须匹配该过滤条件,跟must子句的唯一区别是,filter不影响查询的score;
GET /topics/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "hometown" } },
{ "match": { "content": "hometown" } }
]
}
}
}
也可以写成
GET /topics/_search
{
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "hometown",
"fields": ["title", "content"]
}
}
]
}
}
}
范围搜索 range
#过滤-range 范围过滤
#gt表示> gte表示=>
#lt表示< lte表示<=
GET _search
{
"query":{
"range": {
字段名: {
"gte": 30,
"lte": 57
}
}
}
}
查询哪些数据包含某个字段
exists
GET _search
{
"query": {
"exists":{
"field": 要查询的字段名
}
}
}
合并查询
GET _search
{
"query": {
"bool": {
must/must_not/should: [
{
"term"……
},
{
"range"……
}
……
]
}
}
}